是时候让流批一体的计算引擎大规模落地了
这是一篇夹杂着这十年个人学习成长史来认知流批一体计算引擎发展与迭代的文章,笔者从一名懵懵懂懂的在校生,学习和旁观着大数据系统领域的发展,到逐步参与其中,进而成为Apache Flink社区的一名committer,走了一个螺旋上升的认知历程:从MapReduce批处理入门,到借助于Spark便捷强大的批处理能力进行机器学习功能库的开发;步入社会在微软推广Spark基于micro-batch的实时计算能力,再到进入阿里巴巴参与Flink的实时计算开发和推广,一路从离线批处理走到了实时在线处理,在离开阿里之后回过头又在公司内做流批一体计算引擎的推广。
毕竟长者有云:个人奋斗当然重要,但是也要顺应历史的进程。
缘起:初窥Apache Hadoop
十余年前,当时big data大数据的概念已经在国内外炒得很火热了,谷歌三驾马车GFS,MapReduce,BigTable分别对应的开源实现HDFS,Hadoop MapReduce,HBase,成为了当时最火热的技术概念,甚至那个时候有人对大数据的认知就是hadoop。我那时候在写的本科毕业论文就是HDFS小文件存储的粗浅优化,由于硕士期间还要做大数据系统相关领域研发,所以也是提前学习了系里的相关课程,我现在还记得用MapReduce实现维基百科的倒排索引课题的繁杂冗余。
当然,人红是非多,当时就有《MapReduce:一个巨大的退步》 来自数据库领域大佬的巨大争议。现在回头看,其实大数据系统要做到易用性,还是得逐渐向成熟的数据库体验取经。
相逢:迅速崛起的Apache Spark,很会技术营销的Databricks,微软内部的大数据技术栈
我到现在还记得2013年秋天,Reynold Xin拿着那个”比Hadoop快100倍的Spark系统“宣传展示架到系里来做宣传报告的场景,当时线下就有老师提问,明明大部分场景达不到这么高的性能优化,这种取名是不是太标题党了。现在回头看,Databricks其实是很会做技术营销的,日后其与Flink的隔空对战 ,与snowflake的点名开撕 也就不奇怪了。
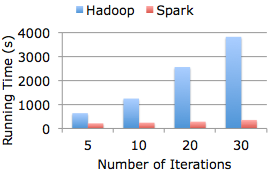
刚接触到Spark时,我就立刻被其身上浓厚的学术圈风格以及相比于Hadoop的更强易用性所吸引了,在我看来,其具有如下的特点:
- 易用的API。相比于MapReduce的古朴API,更丰富的算子可以大大提高易用性,缩短代码行数,避免手搓轮子的痛苦了。
- DAG的引入,可以进行很多shuffle优化,缩短运行时间。
- 可以使用内存缓存部分数据,在迭代运算的机器学习场景可以获得明显的性能提升。
- 使用scala语言开发,有很多语法糖,很cool。但以现在的角度看,scala在不断地加新特性,却没有务实和可维护的态度,连大版本之间的二进制兼容性都舍弃了,整个语言本身还是充斥着学术性实验性的特点,也很难说发展到现在,Spark绑在scala上是否还是一件好事。(Flink社区已经打算舍弃scala了 )
2014年时候,机器学习和AI的概念正值重燃火热风光一时无两,我们实验室想着机器学习的很多底层计算逻辑是一些矩阵运算,所以用Spark结合成熟的科学计算库 ,开发了一个在小圈子里面还算有点热度的分布式矩阵计算库:Marlin 。后来实验室师兄把这个带到了第三次Spark Beijing meetup上做分享,当时在微软亚洲研究院用Spark做分布式机器学习算法的Hucheng看到这个talk之后,也邀请我们去微软北京实习。因为那时候我是一名沉浸式正版xbox玩家,所以能去微软实习还是很开心的,可能也是我这些年工作以来接offer最开心的一次。
2014年底,我踏上了进京的火车进行了为期半年的实习,也是在这段时间,我开始接触到大型企业中的非开源大数据系统解决方案:微软的cosmos和SCOPE,前者可以理解成是hadoop,后者可以理解成是与C#环境结合更好更易用的hive。其承载的数据量和易用的类SQL查询,是当时开源Hadoop生态还不足以达到的,这也让我也认识到不能唯开源是论。实际上现在国内的大型互联网公司,尤其是对分布式存储有要求的,其实都有自研的系统或者魔改的HDFS才能满足更大的数据量要求。顺带一提,2015年SCOPE的老大周靖人跳槽去了阿里巴巴,这在当时公司内还是很令人震惊的消息,也算是中美科技圈的华人人才流动的一个缩影。
我实习的那半年,也是Spark meetup在北京频繁举行的时间段,以现在各家公司对开源技术的商业化认知,Databricks在那几年自己没怎么花钱,却可以让Spark在北京、上海和杭州顺利举行了多次meetup的场景,已经很难再复现了。所以现在想来,当时大家还是抱着比较纯粹的技术交流目的和热忱。其中因为微软北京的shared data组也在公司内使用和推广Spark,所以也提供了几次meetup场地。只可惜Spark Beijing meetup组在2017年关停了,现在就连Spark官网上的社区活动页面也没有北京meetup信息了,那些年在现场火热的讨论场景似乎就只能成为记忆的一部分。
我还记得实习期间的一次讨论,由于当时并没有彻底理解本质,今天回过头看,其实就是流批一体的讨论:mentor在用Spark实现LDA之类的算法时,嫌弃Spark切分stage的执行方式有的时候由于部分慢节点的shuffle write太慢,而导致机器学习的速度不如预期。就问我Spark的各个stage之间是否可以流水线一样地执行,当时我认为这个对Spark的整体数据交换架构改动太大,不方便修改。实际上,这个问题的本质其实是Flink中blocking v.s pipeline shuffle,并在较新的Flink版本中,引入了hybrid shuffle,我们下文再详细展开阐述。
后来我们基于那个分布式矩阵库的思想整理形成了论文 ,并在CCF-A类的IEEE TPDS上被录用,也算是给自己短暂的学术生涯留下了一个脚印,所以我还是很感激Spark的,没有这个系统,就很难有这篇论文的基础工具了。
挣扎:Spark streaming,想说爱你不容易
实习结束之后,我也顺利拿到了微软shared data组的正式offer,开始了自己步入社会的工作之旅。前面讲到微软曾经多次Spark Beijing meetup的活动提供了场地,原因就是shared data组在Bing部署Autopilot(类似k8s的部署系统)上面的一堆windows机器上提供了spark的集群服务(你没看错,这个Spark集群是运行在windows环境上的),希望借着火热的开源活动,提升其在公司内的影响力。很可惜,由于公司内有着非常强大的cosmos生态,Spark相比其并没有在大规模数据处理上展现优势,所以组里的法国PM对外做宣传时,会着重宣传这个系统在1-100TB的规模内,可以数分钟以内对数据进行处理。即使这样,也依然在公司内部的推广举步维艰。幸运的是,很快组里找到了一块当时cosmos还没有涉及的领域:实时计算领域。所以我进入工作之后,主要就是在Spark streaming上挣扎了。说是挣扎,主要有如下的原因:
- 没有很好的反压机制,当数据激增时,内存激增,Spark集群很容易crash,由于实时作业理论上是一直运行的,但是我印象中当时很难有作业可以稳定地运行超过一个月。
- 没有增量checkpoint机制,当数据规模一大时,整个分布式RDD需要持久化checkpoint时,系统很不稳定。
- Spark集群运行在windows环境上,总会遇到一些奇奇怪怪的问题,这个不怪Spark了,只能说那时候微软Bing的部署环境与开源生态不怎么兼容。
系统不稳定,业务推广受限,自然就干得不开心了,那个时候总感觉自己是微软这个浩大巨轮中的一颗小螺丝钉,最核心的系统又被美国总部把持,自己只能做些边角料的活。当时部门的manager Haitao跟阿里的计算平台事业部实时计算部门的老大蒋晓伟(花名量仔)是同学关系,后来他也跳槽到阿里做当时刚刚上线不久的Blink系统。所以当2017年的初夏我还在日本度假时,收到Haitao的”挖人“微信那刻,我内心就毫不犹豫的答应了,不为其他,只是想在一个大公司中做最核心的系统。
全情投入:Blink & Flink,惊鸿中的一撇
Blink本意是”眨眼“,是阿里基于Apache Flink做得大规模二次开发实时计算系统,关于阿里巴巴为什么在内部已经存在JStorm、Galaxy、iStream等三个实时计算系统的情况下,最终会选择基于Flink做技术选型和迭代,网上其实有很多关于实时计算部门的先后两位主负责人蒋晓伟和王峰(花名莫问)的文章 ,介绍了这一过程,这里就不展开了。不得不说,还是需要佩服前辈的前瞻性技术眼光。
进入阿里后,我第一震惊的就是当时阿里已经存在了稳定运行长达一年以上的Blink作业,相比于之前Spark streaming跑一个多月都够呛的情况,无疑是质的飞跃。我在Blink实时计算引擎中负责状态state部分的研发,如果对标批处理的话,其实就是如何用本地存储实现map-reduce阶段的聚合逻辑。我觉得Flink可以强于Spark的流式计算引擎(包括后来重构的Spark structured streaming)的原因主要是如下几点:
- 设计理念不同带来的延迟上限不同。Flink是streaming first,流式作业的算子是在获取到资源后,一直运行的,这样子可以在算子之间进行数据交换时,形成pipeline流水线的数据传输,自然就可以实现毫秒级别的延迟。而Spark则是在批引擎上构建流式计算,所谓micro-batch的架构,其算子在需要map-reduce时,仍然是切分stage的,只能前面一个stage执行完成后,才能执行下一个stage,自然是无法实现毫秒级别的延迟。当然,这也有点好处,就是在可以接受的延迟情况下,能够节省一些资源(毕竟算子不是一直在运行的)。下图来自Aljoscha后来在做API重构时撰写的文章 ,当你更面向流式计算时,你应该申请更多的资源,让算子一直在运行:
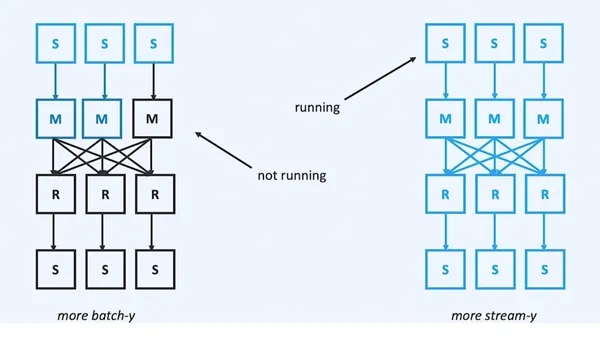
- 设计理念不同带来的shuffle实现不同。Spark的shuffle来自MapReduce的经典理论,数据传输被切割成了经典的两阶段:根据key划分的map端写磁盘以及reduce端从磁盘读,这个的好处就是实现简单且稳定。而Flink由于是streaming first,所以数据传输是通过上下游task的网络buffer直接连接的流水线模式,聚合的逻辑被主要在下游reduce端(在Flink中就是keyBy 算子之后)的状态中进行处理。这个的好处就是可以达到低延迟,坏处就是这个状态的实现比较复杂,尤其是为了达到低延迟,状态后端(state-backend)需要在性能和capacity上做一个trade off,这也是为什么大规模实时作业需要使用RocksDB state-backend来解决基于on-heap内存的state-backend的稳定性问题。Flink这种数据交换方式带来的另一个非常大的优点,就是天生实现了反压机制(backpressure),上下游task的网络数据buffer队列形成了一个经典的生产者-消费者模型,当下游的消费能力不足时,下游无法向buffer队列中放置数据,整个作业就形成了一个反压的状态,也就不会继续从source端消费数据,避免了数据激增时带来作业的不稳定。至今Spark也依然缺乏一套完善的反压机制来提升稳定性。
- 更轻量的checkpoint机制。重构后的spark structured streaming也引入了state,来规避旧版本spark streaming需要将整个RDD持久化带来的不稳定问题。但是因为micro-batch的机制,实际上这些state在开启checkpoint之后,不得不在每个batch结束时对数据进行commit持久化,而不像Flink借助于async checkpoint barrier,可以在任意时间轻量级地执行checkpoint,这也是Flink早期在学术圈的亮点之一 。
2018年,随着Flink Forward Asia的召开,阿里也着手准备收购Flink背后的初创公司data-artisans,并在2019年初以9000万欧元的价格收购,改名为ververica。当时我们觉得这笔钱花得还是挺划算的,阿里收购ververica之后,就开始了企业版与社区版的融合之路,包括捐赠Blink(我们内部已经迭代到Blink-3.x版本了)到Flink社区,与德国团队合作,打造企业版Ververica Platform等等。只是当时大家多少有点担心这批欧洲朋友是否会像很多开源技术公司一样,二次创业,让阿里花了一笔冤枉钱。这里面有很多故事,以后有机会我再写文章讲讲吧。
2020年,我也终于成为了一名Apache Flink committer,主要负责Flink state&checkpoint相关的模块。
新篇章:为什么说现在是推动Flink流批一体的计算引擎大规模落地的时刻了
2022年,我因为个人原因离开了工作了近五年的阿里,换了一座城市,开启了职业生涯的另一段旅程,而我着眼的问题也从Flink流式处理中的状态和容错,放眼到Flink整个系统上。这里我将尝试性地回答如下的几个问题,来阐述为什么我认为现在是推动Flink流批一体的计算引擎大规模落地的时刻了。
流批一体的计算引擎可以带来什么
Flink在早年的论文中,也宣称自己是Stream and Batch Processing in a Single Engine ,但实际上二者其实是两套不一样的API:DataSet和DataStream(见下图)。对于用户而言,除了减少维护一套集群,在代码编写层面是完全不同的体验,无法在企业中发挥最大的价值。
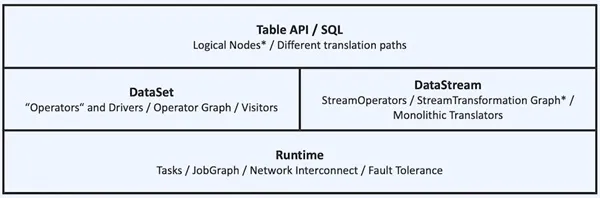
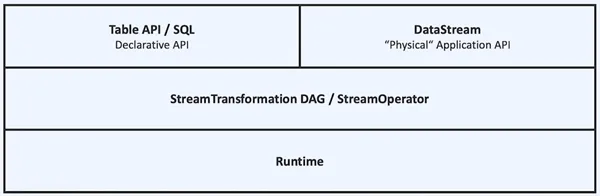
而随着Blink被捐献到Flink社区,量仔老师在2015年就畅想的”流批统一“的计算引擎就开始了相关的重构之路,目前随着DataSet API被deprecated,现在的API架构如下图所示;对于用户来说,只要使用一套统一的DataStream或者Table API,一套代码就可以实现面向批处理和流处理优化的作业(大部分可以通过source进行自适应推断执行模式),减少了需要维护的技术栈,减少了数据口径对齐的压力,大大提高了开发效率。尤其是一些流批融合场景,例如索引数据的生成场景,既需要先前的全量数据,也需要实时的数据索引,一套API可以大大提高开发过程中的效率。
为什么是Flink适合做这个流批一体的引擎
前面其实已经讨论了很多流式计算与批式计算的差异点,在流式计算上为了在低延迟的情况下实现在批处理上习以为常的聚合计算,引入了状态、changlog流、支持exactly-once的轻量异步checkpoint容错、watermark、反压、pipeline shuffle等等机制。可以简单理解成在设计和实现Flink系统时,需要考虑的问题更复杂,所以当其”向下“兼容实现批处理时,就形成了某种意义上的降维打击。所以当Flink社区终于可以抽身开始发力批引擎时,自然是可以看见的水到渠成的事情。而在目前开源方案中,Flink已经成为了实时计算的事实标准,其着力增强批处理引擎自然是最适合的。
现在Flink的流批一体做到了什么程度
在我看来,一个面向当前大数据生态的优秀批处理引擎,需要在shuffle的能力、复杂SQL的解析、hive的兼容性、开箱即用的易用性以及执行性能上均有所涉猎:
- shuffle的能力:Flink的批模式shuffle走了一条与当年Spark类似的发展路径,先实现了hash-based的shuffle策略,然后在Flink-1.13实现了sort-based的shuffle策略,并在Flink-1.15正式成为默认的策略。我仿佛看到了当年2014年底,Spark社区在hash shuffle的基础上引入了sort shuffle,并在2016年Spark正式drop了hash shuffle的历史进程。同时Flink也补全了remote shuffle service的能力,并在Flink-1.16引入了hybrid shuffle作为流批融合的新特性。
- 复杂SQL的解析:目前已经feature freeze的flink-1.17与Spark-3.3的SQL相关功能对比可以参考文档Feature Comparison: Flink Batch vs Spark Batch,整体在功能生已经呈现基本追上之势。
- hive的兼容性:Flink社区支持了hive方言以及相关hive生态的补充,其兼容性在hive qtest上达到94%左右。
- 开箱即用的易用性:Flink-1.15引入了adaptive batch scheduler,可以自适应地判断作业的并发度,省去了手工配置的麻烦。
- 执行性能:Flink-1.16引入了推测执行机制,规避慢节点带来的性能影响。目前在TPC-DS上的测试性能与开源Spark相比已经是较为接近,基本目标在Flink-1.18中80%的query可以达到或超过Spark的性能。当然Flink社区也有在与Velox社区探讨,实现native engine的可能性。
目前在业界,诸如阿里、字节、蚂蚁、快手、虾皮等公司已经有数千乃至数万级别的Flink batch作业在线上运行,从上面的对比可以看出目前Flink社区这一块仍然有一部分的工作需要完成,因而这个时候加入Flink社区在已有的基础上进行相关的开发是一个很好的时机。所以现在是时候推动让流批一体的计算引擎大规模落地了!
推进Flink流批一体的落地,开源社区在行动
目前Flink社区也创建了一个flink-sync的google group,在每双周三举行Flink batch的交流会,2月22日讨论Flink Batch的roadmap,欢迎大家参与!
参考
- MapReduce:一个巨大的退步 https://courses.cs.washington.edu/courses/csep544/21sp/papers/map-reduce-step-backwards-2008.pdf
- Databricks 挑战 Flink https://www.databricks.com/blog/2017/10/11/benchmarking-structured-streaming-on-databricks-runtime-against-state-of-the-art-streaming-systems.html
- Flink回击Databricks https://www.ververica.com/blog/curious-case-broken-benchmark-revisiting-apache-flink-vs-databricks-runtime
- Databricks:消除数据库基准测试的反竞争条款 https://www.databricks.com/blog/2021/11/08/eliminating-the-dewitt-clause-for-database-benchmarking.html
- snowflake:行业标杆 诚信竞争 https://www.snowflake.com/blog/industry-benchmarks-and-competing-with-integrity/
- FLIP-256: Drop scala API https://cwiki.apache.org/confluence/display/FLINK/FLIP-265+Deprecate+and+remove+Scala+API+support
- BLAS https://netlib.org/blas/
- 基于Spark的分布式矩阵计算库,这个名字与Matrix前两个子母相同,其本意”枪鱼“感觉也比较酷 https://github.com/pasalab/marlin
- Improving Execution Concurrency of Large-Scale Matrix Multiplication on Distributed Data-Parallel Platforms https://ieeexplore.ieee.org/document/7884988
- 量仔的Blink之旅 https://zhuanlan.zhihu.com/p/54262989
- Flink 推动者莫问:扛过三年双 11,团队半年贡献 120 万行开源代码 https://www.infoq.cn/article/KgJITFdbhXwI53QFRY3j
- 重新思考Flink的API https://www.infoq.com/articles/rethinking-flink-api/
- VLDB'2017 state management in Flink https://www.semanticscholar.org/paper/State-Management-in-Apache-Flink%C2%AE%3A-Consistent-Carbone-Ewen/6fa0917417d3c213b0e130ae01b7b440b1868dde
- Stream and Batch Processing in a Single Engine https://www.semanticscholar.org/paper/Apache-Flink%E2%84%A2%3A-Stream-and-Batch-Processing-in-a-Carbone-Katsifodimos/ab18dc8b12ab8db6c939ec671bc1f74d6655f465