是时候准备结束数仓领域流批一体的讨论了---增量数仓系列其二
书接上文(由于工作等原因,两篇文章之间拖得有点久)离线数仓近实时化的成本问题— 增量数仓系列其一
我们的上篇文章,主要是理论分析,我们去年使用Flink这种实时计算引擎的思路来做了ODS层—>DWD层的通用近实时化,相关的思考与总结也在FlinkForwardAsia2023上做过相关分享1 ,发现存在如下的问题:
- 对于离线全量表(也往往是最终的产出表,全量表方便分析师查询分析),这在增量计算场景中是存在加工优势的,但是以Flink为代表的通用实时计算引擎在聚合和关联类操作,存在state TTL是无穷的问题,这在embedded state-backend为基础的Flink而言,是无法接受的。
- 对于离线天级增量表,这在上文中,已经分析出其在加工成本上是没有优势的。所以问题就是如何降低额外的计算/存储成本,但是在离线加工ODS —> DWD层,往往需要涉及left join等会产生回撤的加工操作,但是以Flink为代表的通用实时计算引擎在这方面存在一些先天劣势。
我们展开讲讲通用实时计算引擎Flink在近实时加工方面存在的成本劣势问题:
- 目前Flink的状态并没有实现存算分离,导致基于LSM tree的RocksDB state在compaction时候,引入大量的IO以及CPU计算,尤其是Flink的checkpoint机制会容易提前触发level compaction的条件(L0层容易在每次checkpoint时flush文件)。目前Flink社区在这个问题上有两个解决思路,一个是状态的存算2分离 ,异步的state compaction不再在计算节点运行。另一个思路是利用changelog state-backend3 ,将checkpoint与state层面的serving解耦开。不过目前二者如何结合,还是一个没有讨论清楚的问题。
- 在很多场景,尤其是数据量小或者进行数据清洗之后的偏应用层的数据层,并不需要秒级延迟,而算子一直在long running带来的开销,以及周期性checkpoint引入的开销其实都是不那么必要。为了解决这个问题,其实一个很好的思路就是使用调度 + 批处理的方式。这其实也合理,对于给人分析的BI领域,并不需要秒级甚至分钟级的延迟。
- FlinkSQL目前的计算模型采用的是基于回撤(retraction)的通用增量计算模型,这个计算范式在Flink的理论基石DataFlow论文4中有比较详细的阐述,回撤意味着先前的计算结果其实是无用的,所以mini-batch实际是降低无用计算的一种优化,社区先后有了mini-batch aggregate5以及mini-batch join6,都可以看做是对回撤模型的一种优化。那我们其实可以更进一步去想,mini-batch的核心优化思想是攒批,并且尽量预先排序来减少不必要的冗余计算,那么我们其实可以直接用批计算 + 一定频率调度的方式来进行加工处理。
如果计算整体的框架依然follow回撤的机制,那么我们依然无法规避现状下大量冗余的状态,尤其Flink是每个算子独享自己的state,这就导致即使做了包含上述的很多优化,却依然面临着较高的计算加工成本。其实增量计算是一个在数据库领域研究了几十年的问题,在数据库领域中,有一个对应的专业术语:Incremental View Maintenance(IVM)7,简单来说就是将用户对表的 转换为基于增量数据 上的增量查询 ,一个最经典的案例就是inner join,我们可以通过下图看到如何将一个传统的inner join改写为基于增量数据的增量查询:





目前Materialize8和RisingWave9分别实现了这种改写的inner join,他们称之为delta join,由于不需要维护内部的状态,仅需要访问原始表的索引进行查询,所以这种也可以强调说是stateless join。
可以看出,这种增量查询的改写其实是非常复杂的,这也就导致了早些年实现一种比较高效的IVM算法即可发布顶会论文,目前postgresql里面outer join的实现就参考了现阿里云CTO周靖人2007年在ICDE上的论文10,而在2023年VLDB的best paper就颁给了第一个给出了数学上完备的任意查询的增量物化视图转换方案:DBSP11,这帮vmware的工程师、科学家也出来创业了一个公司Feldera,将论文中的算法开源了单机实现12。不过虽然DBSP的实现证明很完善,但是其依赖了z-set来做各种中转,在目前的实现下,还是需要依赖一个比较重的embedded state。
目前在工业界,有国外Snowflake dynamic tables13和 Databricks delta live tables14为代表的已经处于preview商用的闭源方案。论目前这一块的能力,从目前文档上展现的Incremental refresh能力,Snowflake吊打Databricks,而当年Google Dataflow论文的一作也已经早早加入了Snowflake,并且在论文15中阐述了他们的部分实现方式(简单来说就是,高效索引元数据、尽可能的增量遍历和查询改写)。
综合以上内容,我结合Snowflake的dynamic tables的产品形态,所最终设想的离线数仓近实时化的正确解如下图所示:
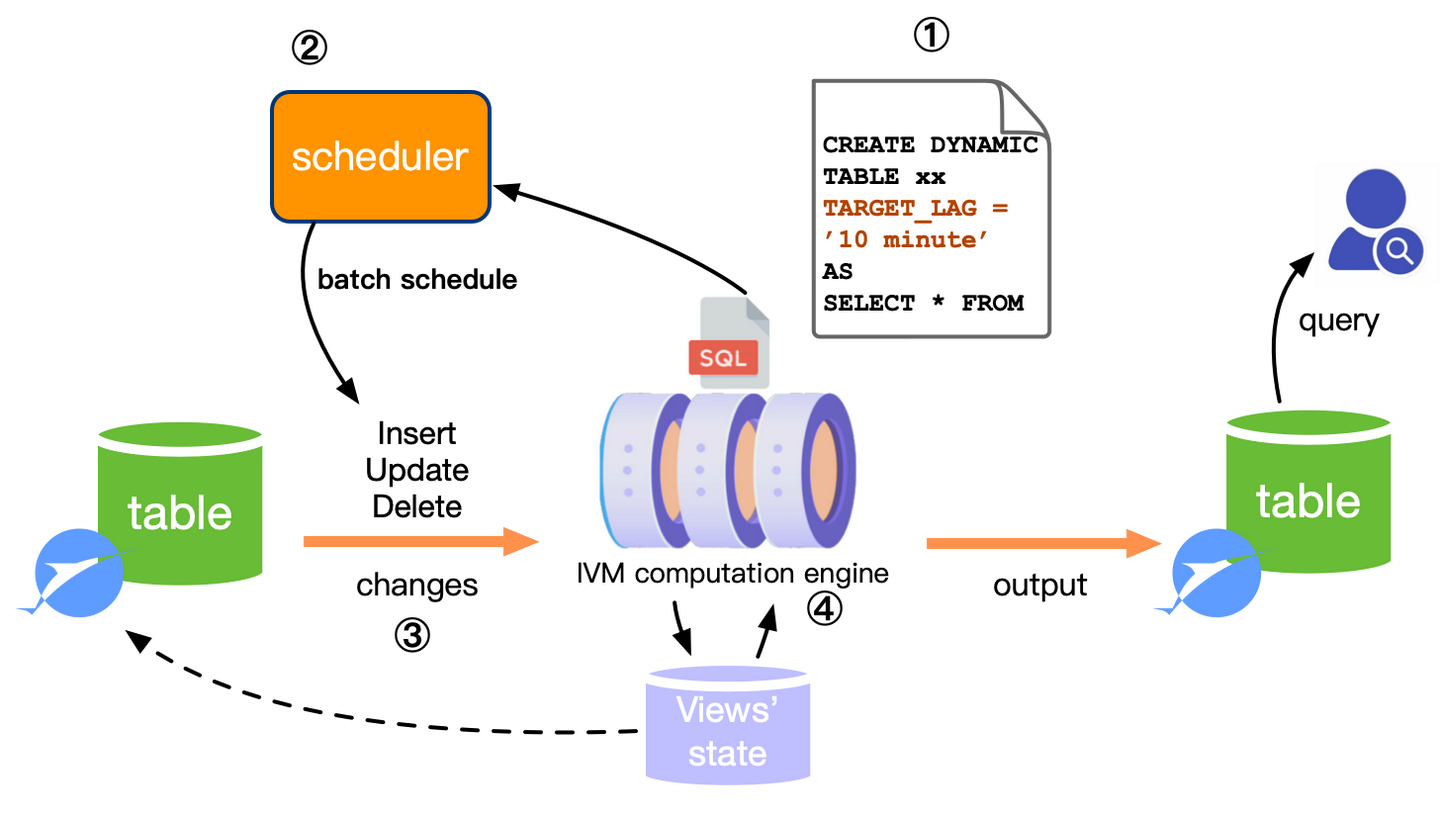
目前Flink社区也注意到这个趋势的发展,所以提出了FLIP-43516搭建整体框架,来推动相关技术的落地。毕竟Flink本身是既支持流式也支持批式处理,用批式调度去做近实时计算也是符合预期的。这里也欢迎各位读者在社区相关mailing list里面积极讨论。
关于流批一体的讨论已经太多了,在纯实时领域,以上的近实时加工是无法替代的,但是在BI领域,近实时加工其实可以涵盖很多场景,如果把时间再拨回到阿里Blink团队初代目leader量仔老师对于“大一统理论”的追求探索:
既然只计算增量,就能得知全量的结果;那么就可以永远用计算增量的方式来表达计算全量。 也就是说:增量计算等效于全量计算;流式计算等效于批处理计算,实时计算等效于离线计算!
我在当下,感觉到长久的讨论与探索逐渐接近了曙光的那一刻,只是与最初的设想不同,我们这里使用了基于lag调度的批计算+增量查询的方式,用接近离线计算的成本,配合增量计算的输入和输出格式,最终达成近实时的延迟效果。
小红书在流批一体与近实时数仓上的实践探索之路 https://flink-forward.org.cn/ ↩︎
FLIP-423: Disaggregated State Storage and Management https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=293046855 ↩︎
changelog state-backend https://nightlies.apache.org/flink/flink-docs-master/docs/ops/state/state_backends/#enabling-changelog ↩︎
Google Dataflow paper https://research.google/pubs/the-dataflow-model-a-practical-approach-to-balancing-correctness-latency-and-cost-in-massive-scale-unbounded-out-of-order-data-processing/ ↩︎
mini-batch aggregation https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/tuning/#minibatch-aggregation ↩︎
mini-batch join https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/tuning/#minibatch-regular-joins ↩︎
IVM https://wiki.postgresql.org/wiki/Incremental_View_Maintenance ↩︎
delta joins https://materialize.com/blog/delta-joins/ ↩︎
risingwave delta join https://www.skyzh.dev/blog/2022-05-29-shared-state-in-risingwave/ ↩︎
Efficient Maintenance of Materialized Outer-Join Views https://ieeexplore.ieee.org/document/4221654 ↩︎
VLDB'23最佳论文: DBSP https://dl.acm.org/doi/10.14778/3587136.3587137 ↩︎
DBSP开源实现 https://github.com/feldera/feldera ↩︎
Snowflake的dynamic tables产品 https://docs.snowflake.com/en/user-guide/dynamic-tables-about ↩︎
Databricks的DLT产品 https://docs.databricks.com/en/delta-live-tables/index.html ↩︎
Incremental Processing with Change Queries in Snowflake https://dl.acm.org/doi/10.1145/3589776 ↩︎
Flink社区关于增量计算框架的提议 https://cwiki.apache.org/confluence/display/FLINK/FLIP-435%3A+Introduce+a+New+Dynamic+Table+for+Simplifying+Data+Pipelines ↩︎