离线数仓近实时化的成本问题--- 增量数仓系列其一
离线数仓近实时化的需求
离线数仓尤其是Spark + Hive的这一套计算存储架构,已经经过了十多年的发展和业界验证,成为了工业界的事实标准。不过随着业界对数据时效性越来越高的需求,逐渐发展出了Flink + 多种类型存储的实时计算存储架构。二者的使用场景不同,成本以及数据加工准确性等方面都有所不同,所以导致了也就是至今依然在业界广为使用的Lambda架构。
(有趣的是,Hive、Spark以及Flink分别先后获得了18、22和23年SIGMOD system award)
无论是从直觉还是对数学美的追求上来说,似乎大家都觉得应该是可以使用例如Kappa架构来达成二者的和谐统一。只可惜,实际上业界落地的case非常少,这里的原因有很多,我们在本文中将从离线数仓近实时化的角度来分析其中的成本问题。
将离线数仓近实时化,所带来的额外成本问题,似乎是一个朴素且直观的结论:如果想要得到更好的时效性,我需要付出更多的一些成本。本文将结合一些现有论文尝试整理回答一下相关成本问题的原理。
借助增量性来公式化离线数仓近实时化的额外成本
经过模型对比,这里选择了SIGMOD'20的论文 Thrifty Query Execution via Incrementability (《通过增量实现更节省的查询执行》) 作为模型阐释。选择的一个原因是该论文的模型更简单、也更容易理解一些(这也是为什么我们这里没有选择Tempura等较为复杂论文的阐述)。 探讨问题的描述:如何在满足数据时效性的前提下,尽量降低整体的计算加工成本。
这个是本文的最核心的理念,实时加工的时效性可以做到end-to-end秒级,而离线数仓加工的时效性是T+1。很显然离线数仓的时效性太差了,但其实很大部分场景下,我们也不需要秒级的时效性,毕竟大部分从数仓中获取信息做决策的人也无法做到秒级响应。所以一方面我们需要提高时效性,一方面,我们也只需要根据实际的诉求来满足时效性即可。关于这个问题的数学表达,我们回头再给出。
以下进入到为了阐述该问题需要的名词定义环节:
Final work:数据加工完毕可以供查询,可以看做数据的时效性,在离线侧对应数据的ready时间。需要注意的是,由于离线数仓往往链路比较冗长,所以最终ADS层其ready的时间不是理想的T+1,而往往是第二天的上午甚至中午。
Total work:所有为了达到数据可以查询所付出的成本,可以看做是作业运行的 core*hour。
为了达到更好的时效性(降低final work),我们往往需要付出更多的成本(additional work)
这里需要结合如下的图进行一个朴素的阐述,例如我们的final work是第二天的上午10点,如果我希望能将数据的时效性提前到第二天的上午7点之前,为了达到这个效果,就意味着我需要进行提前计算,由于提前计算的结果与最终结果并不完全一致,导致这里面的一些工作是额外付出的成本,也就是相当于增加了addition work。至于为什么提前计算的结果与最终结果并不完全一致,我们可以用max这个聚合函数举例,其中间结果的max值,不一定代表以天为维度的最终结果的max值。换言之,存在一些中间的“无用”加工。这里的所谓无用加工,在Flink这种通用流计算框架中,我们称之为changelog模型,那些“最终无用”的中间输出结果,会发送update before 的信息到下游,提醒下游将之前的结果删除,也就是回撤 之前发送的消息。

Query path:执行query加工的数据交换节点、数据读取和数据输出节点。对应Flink里面的一个chained算子节点,或者是Spark里面的stage。在最朴素的算法中,不同的算子之间可以决定攒多少数据再下发给下游,通过调整每个算子的相关配置,可以实现一个动态最优。Flink里面实时场景下,默认不攒数据,per record下发,时效性往往最高,但是额外计算成本也是最高;而在mini batch场景下,我们可以在每个batch中,通过加工计算,规避掉一些提前发下去的无用加工。
Pace:每个query path上,pace=1意味着只执行一次(对应离线场景仅最后批量计算一次),pace=k 意味着每收集 1/k 的数据才下发(k越大,增量计算越频繁,往往付出的额外代价越高)
Incrementability:增量性。我们可以通过提前增量计算来降低final work,也就是提高数据的可见性。但是这个是要基于成本考虑的,所以我们使用 benefit of extra total work 来衡量Incrementability:
这里选择了简化整个加工模型,仅仅通过pace这个单一变量来衡量Incrementability, 相比于而言,在该query path上会产生不一样的Incrementability效果。
Incrementability = ∞ 完全增量化:没有回撤问题的操作,例如filter,map等,先前的增量计算是不会浪费的,为了提高时效性,不需要付出额外成本。
0 < Incrementability < ∞ 部分增量化:存在回撤操作,先前增量计算是可能后来不再需要的,所以为了提高时效性,是需要付出额外成本的。包括大量的聚合运算和关联运算。
对我们所探讨问题(如何在满足数据时效性的前提下,尽量降低整体的计算加工成本)的公式化阐述:
整个的成本模型是在限定时效性系数 的前提下,尽可能降低total work。用近实时数仓的描述就是在一定时效性条件的前提下,尽可能降低成本。例如我们的系数是0.7,也就是假设上午10点数据ready,我们需要至少提前到上午7点的情况下,如何调整不同query path上的pace来尽可能优化成本。公式里成本右侧的 表示批处理情况下,所有运算仅计算一次(pace为1)的离线数仓场景。
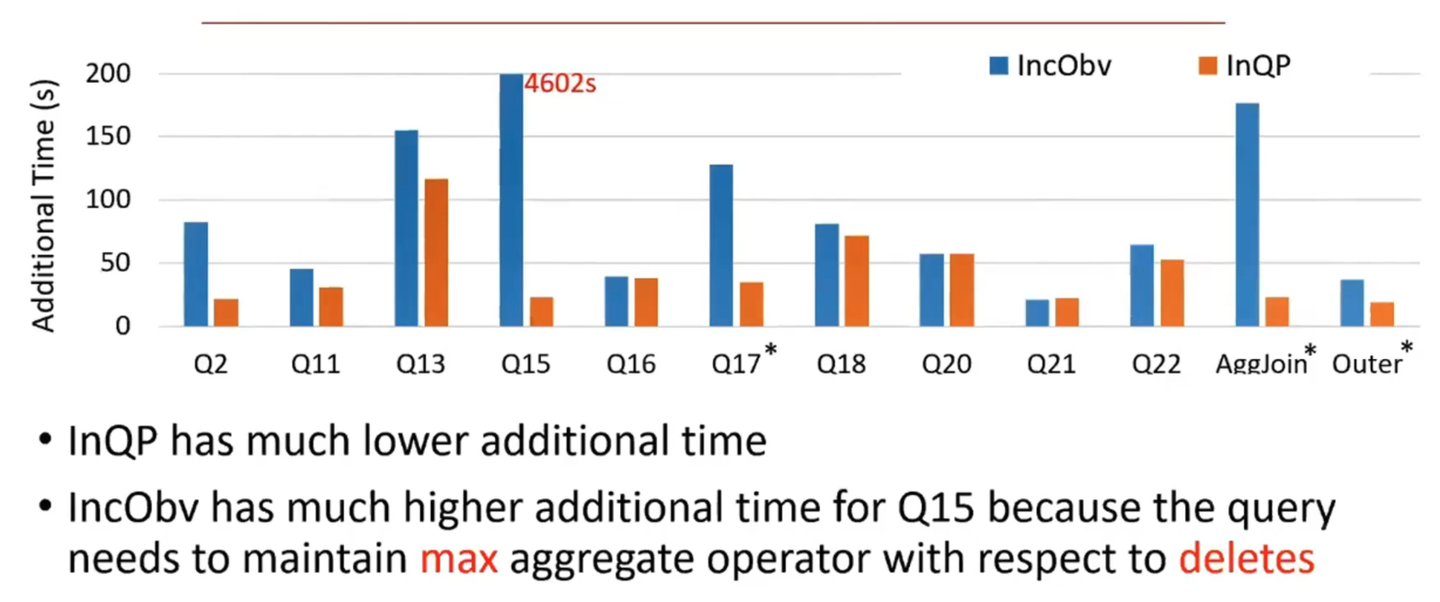
论文里面的优化方式是根据算法配置不同query path的pace值,来得到一个最优的解,下图左侧蓝色是固定所有query path都是同一个pace值(对应的就是spark的固定micro-batch size)得到的baseline,橙色的则是优化后的算法。例如TPC-H的Q15存在max计算的回撤情况,而导致其所要付出additional work成本很大。
我们同样可以用该理论解释为什么partial update这种方式的加工成本是低廉的。如果使用了数据湖的partial update,那么Flink计算的additional work(我们仅论证left join相关操作,其他具体字段加工产生的回撤,暂不考虑)就为0了,而数据湖则在compaction间隔采用batch的方式对left join的行为进行加工,相当于将pace尽可能降低,总体成本就可控了。
理论指导实践
分析完成本模型,那么回到目前离线数仓近实时化的场景:
| 每日的增量表情况 | 输入数据量 | total work | total work中的additional work分析 | final work | pace |
|---|---|---|---|---|---|
| 离线加工 | Size(day_inc) | 数据ready时再trigger: | 0,没有回撤问题 | 数据ready时间较晚: | 1 |
| 以Flink为代表的的通用实时加工 | 与离线相同=Size(di) | 由于存在聚合加工引入的additional work: > | 对于聚合,存在回撤;对于DWD层打宽的left join,存在回撤;中间状态为了达到较好的读效果,引入的compaction而产生的写放大也是成本。Cost(t’) > 0 | 数据ready时间可以提前 < | source —> 聚合算子以及source —> join算子的pace都接近∞ ,也就是来一条eager处理一条;聚合算子 –> 下游算子的pace为k,由mini-batch size决定 |
| 全量数据表情况 | 输入数据量 | total work | total work中的additional work分析 | final work |
|---|---|---|---|---|
| 离线加工 | Size(full) | 数据ready时再trigger: | 0,没有回撤问题 | 数据ready时间较晚,一些重要表也需要到凌晨3点 |
| 以Flink为代表的的通用实时加工 | 增量数据Size(day_inc) < Size(full) | 由于处理的数据量小于全量表,所以成本可能会小于 <? | 对于聚合,存在回撤。对于DWD层打宽的left join,存在回撤。中间状态为了达到较好的读效果,引入的compaction而产生的写放大也是成本。 > 0 | 数据ready时间可以提前,在不考虑跨云传输成本的前提下,可以提前很多< |
可以看出,对于全量数据表(也就是数据从上线之初就一直存在的数据表)而言,通过实时加工来实现增量数仓,是存在理论上的成本优势,但另一个问题也很明显,以Flink为代表的的通用实时框架,在实时处理上,由于是全量数据,所以stateful的算子需要存储永久的状态,这个对于Flink的计算加工模型而言是不可接受的(目前LSM的compaction对于这种无穷TTL是极不友好的),即使可以通过尚未开发的Flink-2.0中的存算分离状态存储 来优化,其成本依然是不可接受的。
那么,我们有啥好的办法呢?请期待增量数仓系列后面的文章。