It's Time to Conclude the Discussion on Stream-Batch Unification in the Data Warehouse Field - Incremental Data Warehouse Series Part II
Continuing from the Previous Article
(Picking up where we left off - apologies for the delay between articles due to work commitments) Cost Issues of Near Real-Time Offline Data Warehouses - Incremental Data Warehouse Series Part I
Our previous article was primarily theoretical analysis. Last year, we used Flink, a real-time computing engine, to implement near real-time processing from ODS layer to DWD layer. Related thoughts and summaries were also shared at Flink Forward Asia 20231, where we identified the following issues:
For offline full tables (often the final output tables, full tables are convenient for analysts to query and analyze), there are processing advantages in incremental computing scenarios. However, general-purpose real-time computing engines like Flink have infinite state TTL issues in aggregation and join operations, which is unacceptable for Flink based on embedded state-backend.
For offline daily incremental tables, we have already analyzed in the previous article that they have no advantage in processing costs. So the question is how to reduce additional computational/storage costs. However, in offline processing from ODS to DWD layer, join operations that produce retractions are often required, but general-purpose real-time computing engines like Flink have some inherent disadvantages in this aspect.
Let’s elaborate on the cost disadvantages of general-purpose real-time computing engines like Flink in near real-time processing:
Flink’s state currently does not implement compute-storage separation, causing LSM tree-based RocksDB state to introduce massive IO and CPU computation during compaction. Especially, Flink’s checkpoint mechanism easily triggers level compaction conditions (L0 layer easily flushes files during each checkpoint). Currently, the Flink community has two solutions to this problem: one is compute-storage separation for state2, where asynchronous state compaction no longer runs on computing nodes. Another approach is using changelog state-backend3, decoupling checkpoint from state-level serving. However, how to combine both is still an undiscussed issue.
In many scenarios, especially small data volumes or application-layer data after data cleaning, second-level latency is not required. The overhead of operators running long-running and periodic checkpoint overhead is actually unnecessary. To solve this, a good approach is scheduling + batch processing. This is reasonable - for BI analysis for humans, second-level or even minute-level latency is not needed.
FlinkSQL’s current computing model adopts a retraction-based universal incremental computing model. This computing paradigm is elaborately explained in Flink’s theoretical cornerstone DataFlow paper4. Retraction means previous computing results are actually useless, so mini-batch is actually an optimization to reduce useless computation. The community has先后 developed mini-batch aggregate5 and mini-batch join6, which can be seen as optimizations for the retraction model. We can think further - the core optimization idea of mini-batch is batch accumulation and pre-sorting to reduce unnecessary redundant computation, so we can directly use batch computing + scheduled processing at certain frequencies.
If the overall framework still follows the retraction mechanism, we still cannot avoid the current large amount of redundant state. Especially since Flink has each operator exclusively owning its state, even with many optimizations mentioned above, we still face high computational processing costs. Incremental computing is actually a decades-long researched problem in the database field. In the database field, there is a corresponding professional term: Incremental View Maintenance (IVM)7. Simply put, it converts user queries on tables $Query$ to incremental queries $ΔQ$ based on incremental data $Δ$. A classic case is inner join. We can see from the figure below how to rewrite a traditional inner join to an incremental query based on incremental data:





Currently, Materialize8 and RisingWave9 have implemented this rewriting of inner join, which they call delta join. Since no internal state maintenance is required, only accessing the original table’s index for queries is needed, so this can also be emphasized as stateless join.
It can be seen that this incremental query rewriting is actually very complex, which is why in earlier years, implementing a relatively efficient IVM algorithm could publish top conference papers. PostgreSQL’s outer join implementation currently references the paper by current Alibaba Cloud CTO Zhou Jingren from 2007 at ICDE10. The 2023 VLDB best paper was awarded to the first to give a mathematically complete incremental materialized view transformation scheme for arbitrary queries: DBSP11. These VMware engineers and scientists also started a company Feldera, open-sourcing the algorithm implementation from the paper12. Although DBSP’s implementation is proven very complete, it relies on z-set for various intermediaries. In current implementation, it still requires a relatively heavy embedded state.
Currently in industry, there are foreign commercial closed-source solutions already in preview, represented by Snowflake dynamic tables13 and Databricks delta live tables14. Regarding current capabilities in this area, based on the Incremental refresh capabilities shown in documents, Snowflake outperforms Databricks. The first author of the original Google Dataflow paper has also joined Snowflake early on and elaborated on their partial implementation methods in a paper15 (simply put: efficient index metadata,尽可能的增量遍历和查询改写).
Combining the above content, integrating Snowflake’s dynamic tables product form, my envisioned correct solution for near real-time offline data warehouses is shown in the figure below:
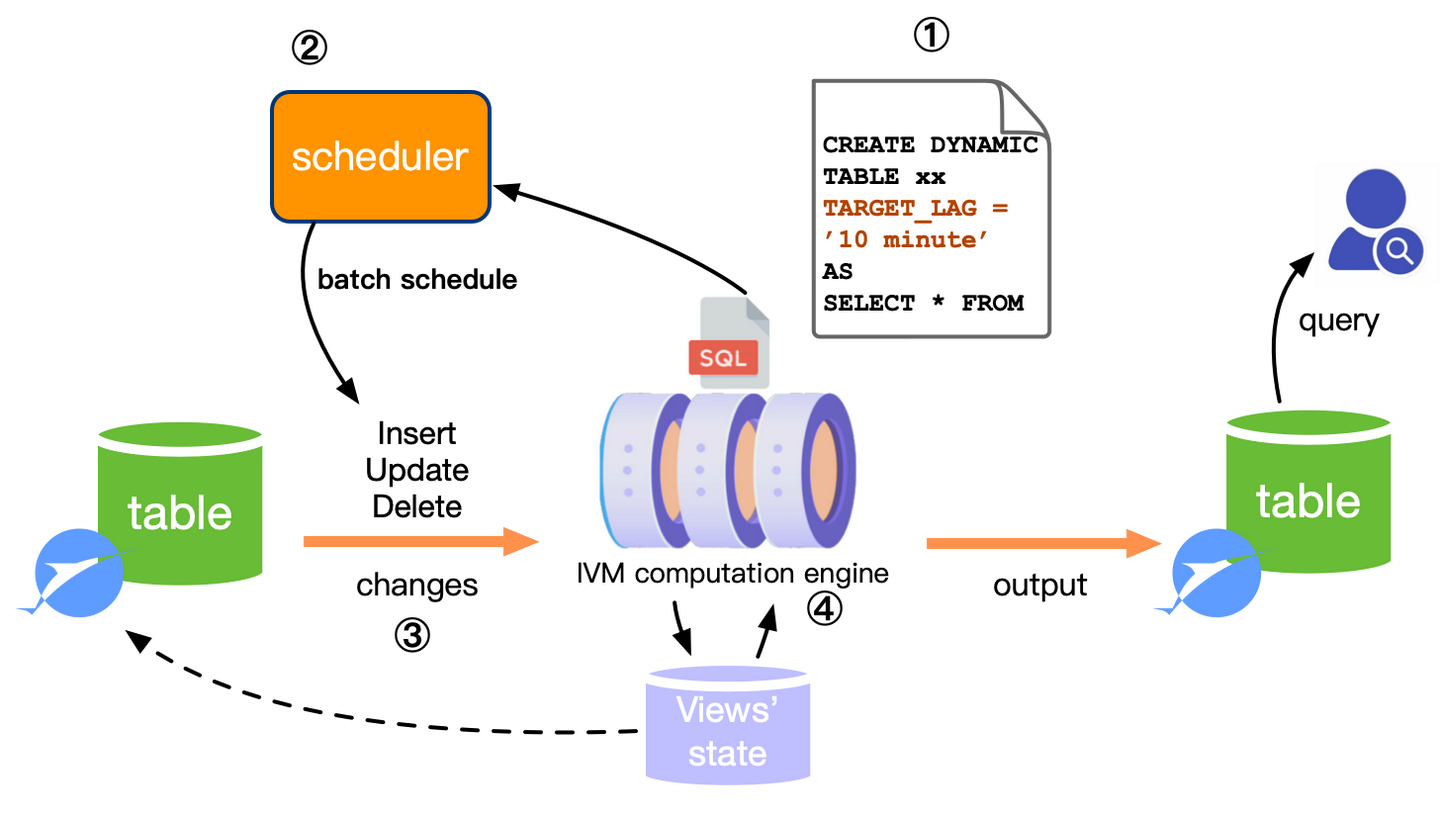
The Flink community has also noticed this trend, so FLIP-43516 was proposed to build an overall framework to promote related technology implementation. After all, Flink itself supports both streaming and batch processing, so using batch scheduling for near real-time computing is expected. Readers are welcome to actively discuss in the community’s mailing lists.
There has been too much discussion on stream-batch unification. In pure real-time fields, the above near real-time processing cannot be replaced. However, in BI fields, near real-time processing can cover many scenarios. If we turn back time to when Alibaba Blink team’s original leader Liang Zi explored the “Grand Unified Theory”:
Since calculating increments alone can know the full results, then we can always express full calculations in terms of incremental calculations. In other words: incremental calculation is equivalent to full calculation; streaming calculation is equivalent to batch processing calculation; real-time calculation is equivalent to offline calculation!
At present, I feel that the long discussion and exploration are gradually approaching the dawn. However, different from the original vision, we use lag-scheduled batch computing + incremental queries here, achieving near real-time latency effects with near-offline computing costs, combined with incremental computing input and output formats.
References
Xiaohongshu’s Practice and Exploration in Stream-Batch Unification and Near Real-Time Data Warehouses https://flink-forward.org.cn/ ↩︎
FLIP-423: Disaggregated State Storage and Management https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=293046855 ↩︎
changelog state-backend https://nightlies.apache.org/flink/flink-docs-master/docs/ops/state/state_backends/#enabling-changelog ↩︎
Google Dataflow paper https://research.google/pubs/the-dataflow-model-a-practical-approach-to-balancing-correctness-latency-and-cost-in-massive-scale-unbounded-out-of-order-data-processing/ ↩︎
mini-batch aggregation https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/tuning/#minibatch-aggregation ↩︎
mini-batch join https://nightlies.apache.org/flink/flink-docs-master/docs/dev/table/tuning/#minibatch-regular-joins ↩︎
IVM https://wiki.postgresql.org/wiki/Incremental_View_Maintenance ↩︎
delta joins https://materialize.com/blog/delta-joins/ ↩︎
risingwave delta join https://www.skyzh.dev/blog/2022-05-29-shared-state-in-risingwave/ ↩︎
Efficient Maintenance of Materialized Outer-Join Views https://ieeexplore.ieee.org/document/4221654 ↩︎
VLDB'23 Best Paper: DBSP https://dl.acm.org/doi/10.14778/3587136.3587137 ↩︎
DBSP open-source implementation https://github.com/feldera/feldera ↩︎
Snowflake’s dynamic tables product https://docs.snowflake.com/en/user-guide/dynamic-tables-about ↩︎
Databricks’ DLT product https://docs.databricks.com/en/delta-live-tables/index.html ↩︎
Incremental Processing with Change Queries in Snowflake https://dl.acm.org/doi/10.1145/3589776 ↩︎
Flink community proposal for incremental computing framework https://cwiki.apache.org/confluence/display/FLINK/FLIP-435%3A+Introduce+a+New+Dynamic+Table+for+Simplifying+Data+Pipelines ↩︎